Embora o assunto esteja completo, os últimos tópicos estão distribuidos em outras páginas conforme links indicados.
Sabe-se que entre as funções básicas de um computador tem-se a necessidade de armazenar, seja de forma temporária/volátil ou permanente/não-volátil (Caso não lembre das funções de um computador leia o post anterior). O armazenamento temporário ocorre durante o processamento (em registradores, memória…) e pode ser descartado logo em seguida. O armazenamento permanente é aquele que ocorre normalmente em disco e permite que os dados sejam salvos e acessados em longo prazo.
Um banco de dados oferece uma visão alto nível da organização dos dados permanentes, mas para serem salvos em um ou mais dispositivos de armazenamento, eles devem estar no formato de bits (ver níveis de um computador no post anterior).
A Figura 01 apresenta a hierarquia de dados, onde se pode observar que um banco de dados é formado por (um ou) diversos arquivos, onde estão inclusos (um ou) diversos registros, que contém (um ou) diversos campos, que são compostos por (um ou) diversos bytes/caracteres que por fim são formados por diversos bits ordenados (8 bits = 1 byte).
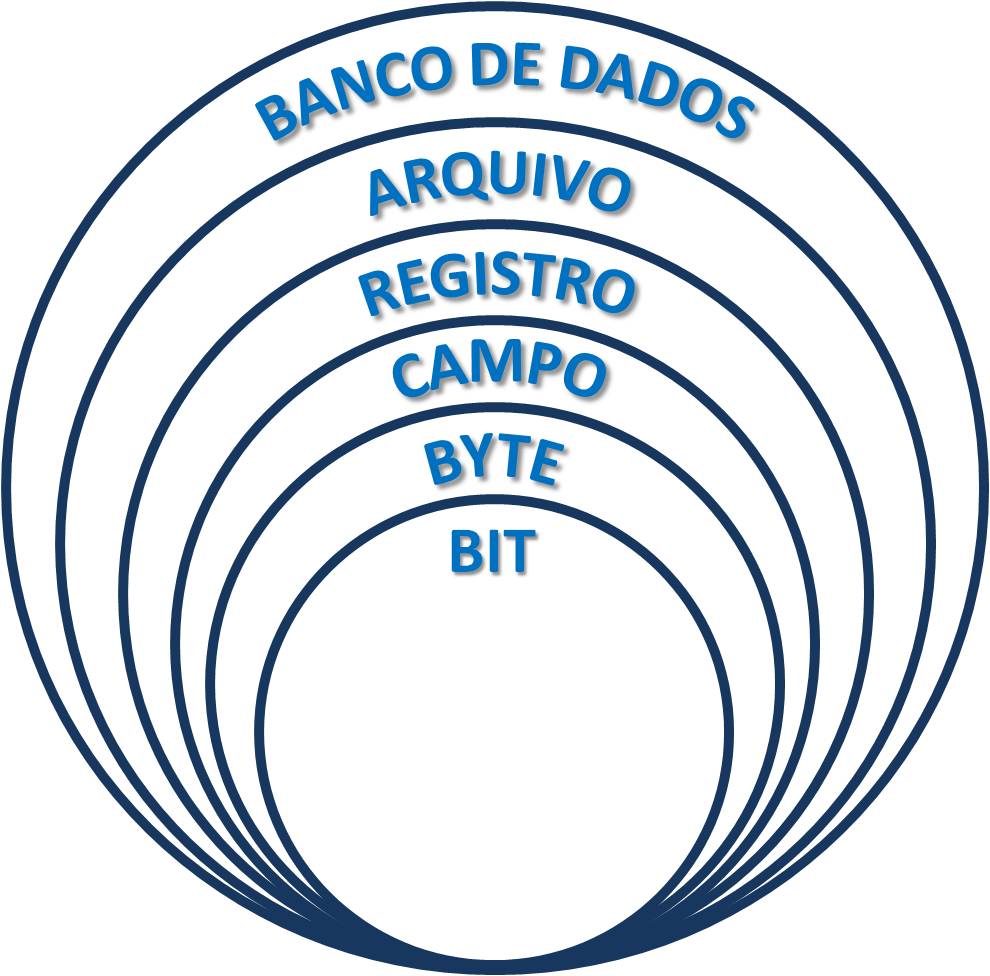
Fonte: https://clickinfoway.wordpress.com/tag/hierarquia-dos-dados/
Para o armazenamento permanente utilizam-se arquivos (imagine um vetor expansível de bits). Um arquivo pode ser visto como uma implementação sequencial de lista linear. Pereira (2007) define arquivo como uma coleção de elementos (registros – mapeados em blocos) que residem em um “disco”. Um arquivo pode ser considerado, conforme visto na Figura 01, um “amontoado” de bits.
Se você entende bem os conceitos de bit, byte, campo e registro sugiro que pule a leitura para o tópico “registros de tamanho fixo”.
No vídeo disponível no link https://www.youtube.com/watch?v=NYuZXg2GA9g você também encontra uma explicação sucinta para tais conceitos, mas siga com a leitura mesmo assim.
Bits
O binary digit (BIT) é a menor unidade de informação manipulável em um computador. Cada bit pode representar 0 (vazio) ou 1 (carregado). As operações que podem ser realizadas sobre um bit são: Configurar valor, ler valor ou inverter valor.
Bytes
Os bytes são formados pela junção de oito bits. A cada oito zeros ou uns, tem-se um byte. Um byte pode representar um valor qualquer que denominamos caracter (para alguns caracteres são necessários dois bytes).
Campos
Com a junção de bits, que formam bytes, temos os caracteres que unidos formam as palavras/campos. Cada campo normalmente é responsável por apresentar o valor de um dado de tipo definido (inteiro, booleano, string…). Apenas para lembrar:
- Um dado isolado representa um valor sem significado. “22” é um dado.
- Um campo já atribui uma denominação a esse dado. Sala: 22. Idade: 22
- Vários campos formam um registro, que permitem obter informações mais precisas e fazer uso desses valores.
- disciplina: Estrutura de dados – horário: 17:00 – sala: 22
- Ir para aula da disciplina todos os dias.
- nome: Maria Santos – endereço: Rua das Flores, Edifício das Rosas – sala: 22
- Entregar um pedido.
- Já a idade, faria mais sentido ter um campo data_nascimento: 01/05/1997 por exemplo e a partir do valor desse campo calcular a idade atual. Poderia comparar com gênero, com região, demais campos do registro (mas deixa essa preocupação para o futuro).
- Definir e enviar ofertas de determinados produtos que possam interessar as pessoas com essa idade por exemplo.
- disciplina: Estrutura de dados – horário: 17:00 – sala: 22
“Um campo armazenado é, informalmente, a menor unidade de dados armazenados” (DATE, 2004).
Registros
Os registros, conforme já definidos são compostos por campos relacionados entre si. Pense em uma tabela para ficar mais fácil (nem sempre serão representados em uma tabela, mas poderão ser reorganizados nesse formato). Os registros de livros na biblioteca, poderiam ter os campos: Código do livro, Título, Autor e Editora (em um projeto real normalizado, com mais campos e dados, Autor e Editora ficariam em outras tabelas, mas deixe essa preocupação para o futuro).
Na Tabela 01 a seguir é possível observar 5 registros de livros com conteúdos relacionados a disciplina de Estrutura de Dados.
- Ex1: O registro do livro de código 1, Computer Sciende Distilled.
- Ex2: O registro do livro Projetos de Algoritmos do autor Ziviani.
Cada linha (chamada tupla na tabela) representa um registro.
Cada coluna representa os valores em determinados campos.
- Exibir todos os títulos de livros disponíveis.
- Exibir o autor do livro de título “Algoritmos”.
| cod | titulo | autor | editora |
| 1 | Computer Science Distilled | Wladson Ferreira Filho | Code Energy |
| 2 | Algoritmos | Thomas Cormen et al. | Gen Lac |
| 3 | Sistema de Banco de Dados | Ramez Elmasri | Pearson |
| 4 | Projeto de Algoritmos | Nivio Ziviani | Thomson |
| 5 | Python Fluente | Luciano Ramalho | Novatec |
Tabela 01: Livros
Normalmente os registros de um arquivo são do mesmo tipo (tem os mesmos campos). Se todos os campos forem de preenchimento obrigatório e tiverem tamanho (em bytes) bem definidos os registros podem ser criados como registros de tamanho fixo, caso tenham diferentes tamanhos, sejam opcionais ou sejam multivalorados podem ser criados como registros de tamanho variável.
Elmasri e Navathe (2011) definem a representação dos registros como “entidades e seus atributos”. Nesse raciocínio, um registro na Tabela 01 representa uma entidade livro e o valor de cada campo define algum atributo do livro (cod, título, autor e editora).
Registros de tamanho fixo
Para serem considerados de tamanho fixo, todos os registros definidos devem ocupar o mesmo espaço no arquivo. O exemplo na Figura 02 apresenta um registro com tamanho de 71 bytes. Cada registro possui os mesmos campos, cujos tamanhos são fixos. Basta o sistema identificar a posição do byte que inicia cada campo a partir da posição do byte inicial do registro.

Fonte: Navathe e Elmasri (2011)
Sim é uma foto do livro!! Se você localizar essas imagens com qualidade melhor, deixe o link nos comentários. Se quiser reproduzi-las, pode enviar pro meu e-mail por favor [email protected]
Observe que todos os campos possuem um tamanho fixo. A cada 71 bytes contados encontra-se um novo registro. Do 1º ao 30º byte de cada registro encontra-se o nome com 30 bytes, do 31º ao 39º o CPF com 9 bytes (pois é! 9 mesmo, provavelmente falha na tradução), do 40º ao 43º o salário com 4 bytes, do 44º ao 47º o código do cargo exercido com 4 bytes, do 48º ao 67º a indicação do departamento com 20 bytes, e do 68º ao 71º a data de contratação com 4 bytes (provavelmente MMAA).
Registros de tamanho variável
Arquivos
Dentro dos arquivos encontram-se os registros, que podem ser de tamanho fixo ou variável. Um cabeçalho/descritor de arquivo carrega as informações necessárias para que o programa de sistema possa acessá-los. Esse descritor contém informações para identificar os endereços dos blocos no disco, descrição de formato (tamanho, tipo e ordem dos campos em um registro), separadores.
Para acessar os registros do arquivo no disco, um ou mais blocos são copiados nos buffers da memória principal. Em seguida, os registros são buscados no buffer. Se o bloco que contém o registro é desconhecido, o sistema deve fazer uma busca linear, ou seja, percorrer o arquivo do início até encontrar o registro (ou até o fim, quando “not found”). Quanto maior o arquivo, mais tempos leva-se para percorre-lo. “O objetivo de uma boa organização de arquivo é localizar um bloco que contenha um registro desejado com um número mínimo de transferência de bloco” (ELMASRI e NAVATHE, 2011).
Arquivo binário
baseado em bytes -> número 5 = 101
Arquivo de texto
em caracteres-> caractere 5 = _ 00110101 (53 que indica “5”).
Processamento de arquivos
As chamadas para processamento de arquivos mudam de acordo com o Sistema Operacional utilizado. A seguir é apresentado um conjunto representativo de operações conforme definição de Elmasri e Navathe (2011).
Open(): Prepara o arquivo para leitura ou gravação. Aloca Buffers apropriados (em geral, ao menos dois) para manter os blocos de arquivos
reset(): define o ponteiro do arquivo aberto para o início do arquivo.
find
read
finNext
Delete
modify
insert
close
- O programa que processa um fluxo é informado sobre o fim do arquivo.
- Final do arquivo (SO)
- um marcador de fim de arquivo (caractere especial) ou
- Armazenamento da contagem total de bytes ou
- Gera exceção ou retorno.
“Python não depende da noção básica do sistema operacional sobre arquivos de texto; todo processamento é feito pelo próprio Python, e é então independente de plataforma”.
f = open('arquivo.txt', 'r')
linha = f.readline()
while linha:
print linha,
linha = f.readline()
f.close()
===
f = open('arquivo.txt', 'r')
while True:
linha = f.readline()
if linha == '': break
print linha,
f.close()
Acesso Sequencial
Acesso Aleatório
Capítulo 11: Arquivos e exceções = https://aprendacompy.readthedocs.io/pt/latest/capitulo_11.html#diretorios
Editores
Os sistemas de edição são programas que permitem aos usuários editar documentos como textos, imagens, diagramas… Esses sistemas normalmente não se preocupam com o gerenciamento de acesso concorrente, pois costumam ser destinados a um único usuário.
Para manter um retorno imediato ao digitar, selecionar, recortar, etc. representações dos dados são mantidos na memória principal (mais rápida que o disco, porém) volátil. Para evitar a perda de dados, muitos editores executam salvamento automático. Nesses casos os arquivos são facilmente recuperados em caso de falha do sistema (SOMMERVILE,XX).
Uma arquitetura genérica de um sistema de edição é exibida na Figura X. Se você compreende as partes, pule a leitura para a próxima seção.
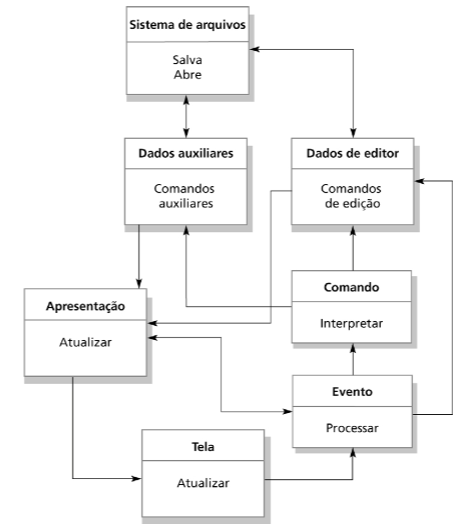
Fonte: Sommerville (ANO)
Tela: monitora a memória de tela e detecta eventos para serem passados para o processador de eventos.
Evento: Acionado pela chamada da tela, deve interpretar e traduzir o evento em comandos apropriados. Em eventos comuns como clique de mouse ou digitação de teclas, a comunicação pode ocorre direto com a estrutura de dados (para agilizar a atualização). Nos demais casos o comando é passado para o objeto responsável pela interpretação.
Comando: processa o comando recebido do eventoe chama o método apropriado para executar o comando.
Dados do editor: Atualiza a estrutura de dados e apresenta os dados modificados.
Dados auxiliares: conjunto de dados necessário que não fazem parte da estrutura de dados, como preferências, estilos, etc.
Sistemas de arquivos: responsáveis pelo gerenciamento dos arquivos (abrir, salvar…).
Apresentação: Acompanha a organização dos dados na tela, invoca refresh().
Linguagens
Meios de Armazenamento
Atividade
Armazenamento em disco
Há diversas técnicas para alocação de arquivos em discos.
Alocação contígua: (contiguous allocation) Os blocos são alocados consecutivamente.
– A leitura é rápida porém é difícil expandir o arquivo.
Imagem
Alocação encadeada: (linked allocation) cada bloco de arquivo contém um ponteiro para o próximo bloco de arquivo.
– É fácil expandir o arquivo, porém a leitura do arquivo inteiro é lenta.
imagem
Essas técnicas podem ser combinadas como alocação de blocos consecutivos em clusters/segmentos ou alocação indexada (bloco de índice + bloco de arquivo).
Sistemas de arquivos
Morimoto (2005) define um sistema de arquivos como “um conjunto de estruturas lógicas e de rotinas, que permitem ao sistema operacional controlar o acesso ao disco rígido”.
O FAT16 é o mais antigo, usado desde os tempos do MS-DOS
Índices
Segundo buscador google, se você buscar por “define: índice”, obterá a resposta do printScreen a seguir.
Um exemplo muito comum de índices são encontrados em livros físicos/impressos. Ao pegar um livro técnico, em qual se busca por determinado assunto, é comum o leitor ir primeiro ao índice. Lá, com a leitura de poucas palavras, é possível identificar se o livro possui o assunto de interesse e em qual página o texto completo poderá ser encontrado. Na sequência é só “navegar” para página indicada e iniciar a leitura.
Imagine se os livros não tivessem índices. O quanto mais demorado seriam as buscas, pois mesmo pulando os capítulos e lendo somente os títulos, ainda seria necessário encontrar o início de cada capítulo para poder ler o título e analisar.
As ISOs por exemplo, embora normalmente sejam adquiridas em sua completude pelas empresas, elas são divididas em partes. De forma que, por meio dos índices é possível pode tomar conhecimento do que cada parte contém e adquirir somente as partes que sejam de interesse.
Definição de chave (cadastro de livros, autores e editoras).
Tipos de índices
Primário ou Secundário
Direto ou Indireto
Denso ou Esparso
https://www.hardware.com.br/livros/hardware/capitulo-hds-armazenamento.html
Extra
Leia o trabalho disponível em https://www15.fgv.br/network/tcchandler.axd?TCCID=6809 (capítulo 6 e conclusão).
2.1. Conceitos básicos e classificação dos meios de armazenamento.
2.2. Estrutura dos discos, operações e tempos de acesso.
2.3. Características dos sistemas de arquivos, interface, vantagens e desvantagens.
2.4. Conceitos de registros, campos e chaves de acesso.
2.5. Manipulação de arquivos, registros de tamanho fixo e registros de tamanho variável.
2.6. Tipos de fluxo de dados, acesso direto, acesso sequencial, sequencial indexado e acesso aleatório
Referências
Carlos E. Morimoto. Sistema de arquivos. 2005 em https://www.hardware.com.br/termos/sistema-de-arquivos
ELMASRI, Ramez e NAVATHE, Shamkant. Sistemas de Banco de Dados. SP: Pearson Addison Wesley, 2011.